从一脑门子问号到把 Table、View、Entity 一锅端: 我做 D365FO Bookmark 插件的拐弯实录 那天领导让我整个小工具,给部门在多个环境 Dynamics 365 Finance & Operations 里查表、看 View、 Entity 数据的时候省点劲儿。目标很朴素,甚至有点土: 生成一个本地 HTML,输个环境 Host,点两下,直接跳 TableBrowser,或者拼好 Data Entity 的 OData 地址。之前是有一个很基础的html的,但是是同事手动维护的,而且很丑,几个项目同时推进手动弄太费劲了。
结果这一脚迈进去,好家伙,真不是我想得那么直给。
这活儿看着像“把元数据列出来”这么简单,实际上中间是一波三折,左一个坑,右一个坑,坑坑不一样,坑坑都挺抽象。尤其是当你这个东西不是跑在 IIS 里,不是跑在普通业务进程里,而是跑在 D365 开发扩展的 Visual Studio 插件上下文里,那很多“平时能用”的路子,到了这儿就开始整活儿了。
这篇就按我当时踩坑的顺序,层层扒开,讲清楚我是怎么把所有 Table、View、Entity 找全的,又是为什么最后选了现在这套实现。
先说目标: 我要的不是“差不多能查”,我要的是“尽可能实时、尽可能准” 我最开始给自己定的标准很简单:
Table、View、Entity 都得能找出来。
逻辑名称和物理名称都得尽量对应上。
不能依赖那些“可能没刷新”“可能有缓存”“可能跟当前模型状态不一致”的来源。
这个插件得独立运行在开发扩展里,别额外引一堆认证库,把宿主环境整炸了。
说白了,这玩意儿不能只是“能跑”,得是“在这个诡异宿主里还能稳稳地跑”。
第一折: 我最先想到查表,结果一上来就被 SQLDictionary 和 SysTableIdTable 整不会了 刚开始我也走过最顺手的思路: 既然 Table 和 View 最终都能落到系统字典、系统表里,那我是不是直接从 SQLDictionary、SysTableIdTable 这类地方抠数据就完事儿了?
听着挺合理,是不是?
可真一上手,我就发现这路子有点虎。
问题不在于“查不到”,而在于“查出来也不一定对”。
原因很现实:
这些数据本身就不是给“当前开发态元数据精确枚举”这个场景设计的。
里面混着很多运行态、同步态、历史态、部署态的信息,数据非常凌乱。
你现在开发机上模型刚改完或者刚换了代码分支,数据库里那份信息不一定跟你当前 AOT 真同步。
Table、View 的名字、标签、最终可用对象之间,并不是简单查一张系统表就能百分百拍板。
这就像你去早市买西红柿,摊主跟你说“都保熟”,你一捏一个软的,再一捏里头还是空心的。不是完全不能吃,但你真要拿它做正经菜,心里发虚。
所以我很快就把这条路否了。
不是因为 SQLDictionary 和 SysTableIdTable 没用,而是因为它们对我这个目标来说,不够“干净”,更不够“实时可信”。
第二折: 那 Entity 呢?实体列表看着现成,结果它也不靠谱 接着我又琢磨,Entity 总有现成列表吧?开发环境里不是能看实体列表么,那我是不是直接走实体列表查询就完了?
结果一试,我又搁那儿直拍大腿。
Entity 列表这个东西,最大的问题不是不好用,而是它要手动刷新。
这意味着啥?
这意味着你眼前看到的“列表”,不一定是当前最新状态。你刚新建了一个实体、改了名字、调整了公开集合名,如果那个列表没刷新,它就还搁那儿装死。
这对平时点点界面问题不大,但对插件来说特别要命。
因为插件一旦生成了不实时的数据,后面你查出来的 OData 地址就可能是旧的、错的,或者压根打不开。那同事点开以后第一反应不是“哦,实体列表缓存了”,而是“这插件是不是拉了”,“这小子又在吹牛b”。
这锅我可不背。
所以 Entity 这边我也放弃了“查实体列表”的思路,转而直接读元数据源头。
第三折: 普通元数据读取思路,在这个插件上下文里不一定能跑 走到这儿,我的想法已经很明确了: 既然系统表不够准,实体列表不够实时,那我就直接读 Metadata。
但接下来新的问题来了。
这插件不是跑在 IIS 里,也不是跑在 D365FnO 的应用业务进程里,它是个独立于 IISExpress 进程外的开发扩展插件,宿主是 Visual Studio 的 D365 开发插件。
这就导致很多“平时你在业务代码里能直接用”的元数据访问方式,到了这里就容易当场撂挑子。
比如我压根不能默认指望那种依赖 IIS 上下文的方式一定可用。你在业务侧、服务侧、甚至某些带上下文的环境里能跑通的东西,到了 VS Addin 这个宿主里,环境就不对味儿了。
所以我最后选的是 Disk Metadata,也就是从磁盘上的 metadata 目录去读。
对应的关键逻辑很清楚:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 private static IMetadataProvider TryCreateDiskMetadataProvider (Action<string > log ){ try { IApplicationEnvironment applicationEnvironment = EnvironmentFactory.GetApplicationEnvironment(); if (applicationEnvironment == null || applicationEnvironment.Aos == null ) { log?.Invoke(R("Output_GetApplicationEnvironmentNull" , "GetApplicationEnvironment returned null or Aos is null." )); return null ; } var packageDir = applicationEnvironment.Aos.PackageDirectory; var metadataDir = applicationEnvironment.Aos.MetadataDirectory; log?.Invoke(RF("Output_ApplicationEnvironmentObtained" , "Application environment obtained. PackageDirectory: '{0}', MetadataDirectory: '{1}'." , packageDir, metadataDir)); var metadataProviderFactory = new MetadataProviderFactory(); IMetadataProvider backupMetadataProvider = null ; if (!string .IsNullOrWhiteSpace(packageDir)) { backupMetadataProvider = metadataProviderFactory.CreateRuntimeProvider(new RuntimeProviderConfiguration(packageDir, false )); } if (!string .IsNullOrWhiteSpace(metadataDir)) { var diskProvider = metadataProviderFactory.CreateDiskProvider(metadataDir); if (diskProvider != null ) { log?.Invoke(R("Output_DiskMetadataProviderCreated" , "Disk metadata provider created successfully." )); return diskProvider; } } if (backupMetadataProvider != null ) { log?.Invoke(R("Output_RuntimeProviderFallbackCreated" , "Disk provider unavailable, runtime provider from storage factory created." )); return backupMetadataProvider; } return null ; } catch (Exception ex) { log?.Invoke(RF("Output_DiskMetadataProviderFailed" , "Disk metadata provider failed: {0}" , ExceptionToLogText(ex))); return null ; } }
这里我为什么更偏向 Disk Metadata?
因为它不依赖 IISExpress 进程上下文。
因为插件运行在 VS 扩展宿主里,这种独立读取方式更稳。
因为它更贴近当前开发机上的模型文件状态。
因为对“我要列出当前开发态的 Table、View、Entity”这个目标来说,它比很多运行时入口更合适。
你要说形象点,那就是: 我本来想走正门,结果发现正门得刷工卡、验身份、看你是不是在 IIS 大院里上班;我后来直接绕到后厨,从 metadata 货架自己点货,反倒利索。
我一开始还天真地以为,Metadata Provider 既然都拿到了,那是不是可以直接整出所有真正的对象,把完整内容一股脑拉出来?
事实证明,想得挺美。
在这里,不能指望直接一次性列出所有真正的 object 内容。更稳妥的办法,是先把名字列出来,再按名字逐个读取。
对应代码非常直白:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 var tableNames = provider.Tables.ListObjects(null )?.ToList() ?? new List<string >();var viewNames = provider.Views.ListObjects(null )?.ToList() ?? new List<string >();var entityNames = provider.DataEntityViews.ListObjects(null )?.ToList() ?? new List<string >();var labelFileNames = provider.LabelFiles.ListObjects(null )?.ToList() ?? new List<string >();int total = tableNames.Count + viewNames.Count + entityNames.Count + labelFileNames.Count;int done = 0 ;onProgress?.Invoke(done, total, R("Progress_EnumeratedMetadataObjects" , "Enumerated metadata objects" )); int degree = Math.Max(2 , System.Environment.ProcessorCount);var options = new ParallelOptions { MaxDegreeOfParallelism = degree };var unresolvedLabels = new ConcurrentDictionary<string , byte >(StringComparer.OrdinalIgnoreCase);var resolvedLabels = new ConcurrentDictionary<string , string >(StringComparer.OrdinalIgnoreCase);var tablesAndViewsBag = new ConcurrentBag<NameMapping>();var entitiesBag = new ConcurrentBag<NameMapping>();Parallel.ForEach(tableNames, options, table => { AxTable t = provider.Tables.Read(table); foreach (var mapping in BuildNameMappings (t.Label, t.Name, labelResolver, id => unresolvedLabels.TryAdd(id, 0 ))) { tablesAndViewsBag.Add(mapping); } int current = Interlocked.Increment(ref done); onProgress?.Invoke(current, total, R("Progress_ReadingTables" , "Reading tables" )); }); Parallel.ForEach(viewNames, options, view => { AxView v = provider.Views.Read(view); foreach (var mapping in BuildNameMappings (v.Label, v.Name, labelResolver, id => unresolvedLabels.TryAdd(id, 0 ))) { tablesAndViewsBag.Add(mapping); } int current = Interlocked.Increment(ref done); onProgress?.Invoke(current, total, R("Progress_ReadingViews" , "Reading views" )); }); Parallel.ForEach(entityNames, options, entity => { AxDataEntityView dataEntity = provider.DataEntityViews.Read(entity); foreach (var mapping in BuildNameMappings (dataEntity.Label, dataEntity.PublicCollectionName, labelResolver, id => unresolvedLabels.TryAdd(id, 0 ))) { entitiesBag.Add(mapping); } int current = Interlocked.Increment(ref done); onProgress?.Invoke(current, total, R("Progress_ReadingEntities" , "Reading entities" )); });
这一步非常关键。
因为“列名”和“读对象”是两个阶段:
先用 ListObjects 拿到一个相对可靠的对象清单。
再用 Read 按名字读取具体元数据内容。
这样能把枚举和解析拆开,控制粒度,也更容易做并行和进度汇报。
如果不这么干,直接妄图一步到位,最后多半就是一边读一边骂街: 这啥呀,这咋还不全,这咋还异常呢,这咋还卡死呢。
这叫别上来就抡大勺,先把菜码齐了再下锅,不然锅里全是动静,没有成品。
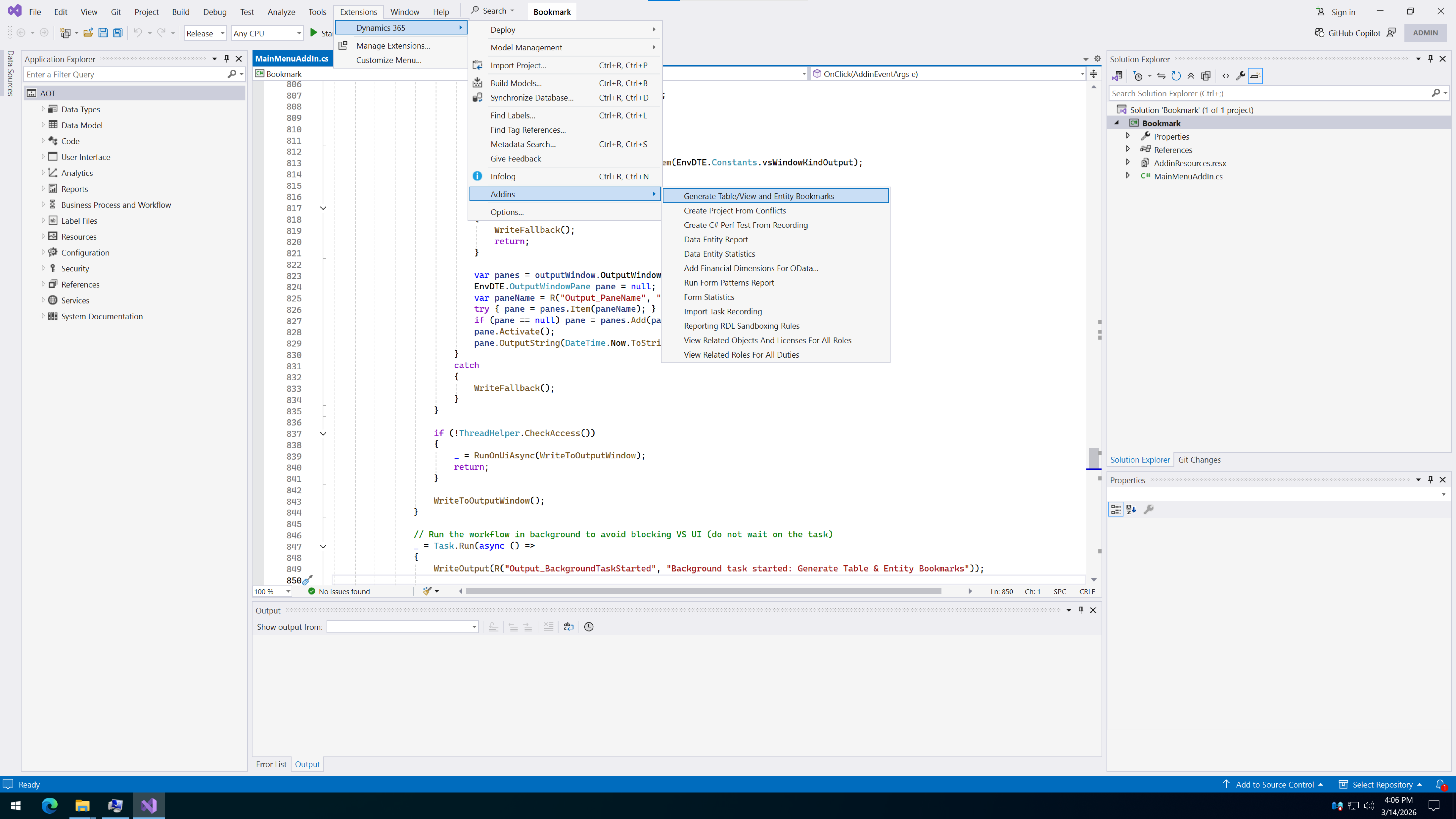
到这儿可能有人会问一句: 既然都是拿 Table 元数据,为啥不用 Microsoft.Dynamics.AX.Xpp.MetadataSupport.GetTable 这类接口?
答案很简单,也很扎心:
因为这玩意儿通常得在 IIS 上下文里调。
我这个插件是跑在 D365 开发插件上下文里的,不在那个上下文里,你指望它像在应用服务里一样丝滑工作,属实有点想多了, 你一用,是也没报错,但是就跟死猪一眼,干怼不动弹。
所以这里我选 IMetadataProvider.Tables.Read、IMetadataProvider.Views.Read、IMetadataProvider.DataEntityViews.Read,本质上是为了规避宿主上下文问题。
也就是说,我不是单纯为了“代码看着统一”才这么写,而是因为:
GetTable 一类方式依赖 IIS 语境。当前 Addin 运行在 VS 宿主,不是 IIS。
IMetadataProvider 这条路径更贴合当前执行环境。同一套 Provider 也方便我把 Table、View、Entity 统一处理。
技术选型这玩意儿很多时候不是“谁更高级”,而是谁在当前场景里不抽风。
能稳定跑完完成任务,比什么都强。
第六折: 名字还不够,我还得把标签翻出来,不然用户看着跟天书似的 当我把 Table、View、Entity 名字都列出来之后,又冒出来另一个问题: 很多对象在 Metadata 里拿到的是标签引用,不是直接的可读名称。
比如一个 Label 可能长这样: @XXX123。
你要是直接把这玩意儿扔给用户,那用户看完第一反应就是: 这啥玩意儿,CPU 序列号啊?
所以我又顺手把 Label File 也一并列出来、读取、解析,构建了一个标签解析器。
对应代码是这么一套,它不是只看对象名,而是把英文标签文件也捎上,一起解析成用户能看懂的名字:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 private static Func<string , string > TryCreateLabelResolver (IMetadataProvider provider, List<string > labelFileNames, ConcurrentDictionary<string , string > map, Action<string > log, Action onLabelFileProcessed ){ try { var labelNames = labelFileNames ?? new List<string >(); int totalLabelFiles = labelNames.Count; log?.Invoke(RF("Output_LabelParsingStarted" , "Label parsing started. Label files: {0}" , totalLabelFiles)); int parseDegree = Math.Max(16 , System.Environment.ProcessorCount * 6 ); var parseOptions = new ParallelOptions { MaxDegreeOfParallelism = parseDegree }; Parallel.ForEach(labelNames, parseOptions, labelFileName => { try { AxLabelFile labelFile = null ; try { labelFile = provider.LabelFiles.Read(labelFileName); } catch (Exception ex) { log?.Invoke(RF("Output_ReadLabelFileMetadataFailed" , "Read label file metadata failed '{0}': {1}" , labelFileName, ExceptionToLogText(ex))); } if (labelFile != null && IsEnglishLanguage(labelFile.Language)) { var localPath = labelFile.LocalPath(); if (!string .IsNullOrWhiteSpace(localPath) && localPath.EndsWith(".txt" , StringComparison.OrdinalIgnoreCase) && File.Exists(localPath)) { var moduleName = GetModuleNameFromLocalPath(localPath); TryLoadLabelFile(localPath, moduleName, map, log); } } } finally { onLabelFileProcessed?.Invoke(); } }); } catch (Exception ex) { log?.Invoke(RF("Output_LabelResolverInitFailed" , "Label resolver initialization failed: {0}" , ExceptionToLogText(ex))); } return id => { var keys = BuildLookupKeys(id); foreach (var key in keys) { if (map.TryGetValue(key, out var value ) && !string .IsNullOrWhiteSpace(value )) { return value .Trim(); } } return id; }; }
这一步其实也进一步说明了,为什么我要走 Metadata Provider 这条路。因为我要的不只是“对象存在”,而是“对象对人友好”。
最终在 HTML 里,我保留了逻辑名和物理名映射,这样搜索的时候两边都能命中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var tableMap = { 'sales order header' : 'SalesTable' , 'customer invoice line' : 'CustInvoiceTrans' }; var tableItems = [ { logical: 'Sales order header' , physical: 'SalesTable' , search: ('Sales order header SalesTable' ).toLowerCase() }, { logical: 'Customer invoice line' , physical: 'CustInvoiceTrans' , search: ('Customer invoice line CustInvoiceTrans' ).toLowerCase() } ]; function resolvePhysicalName (inputValue, map ) { var v = (inputValue || '' ).trim(); if (!v) return '' ; var key = v.toLowerCase(); if (map && map[key]) return map[key]; return v; }
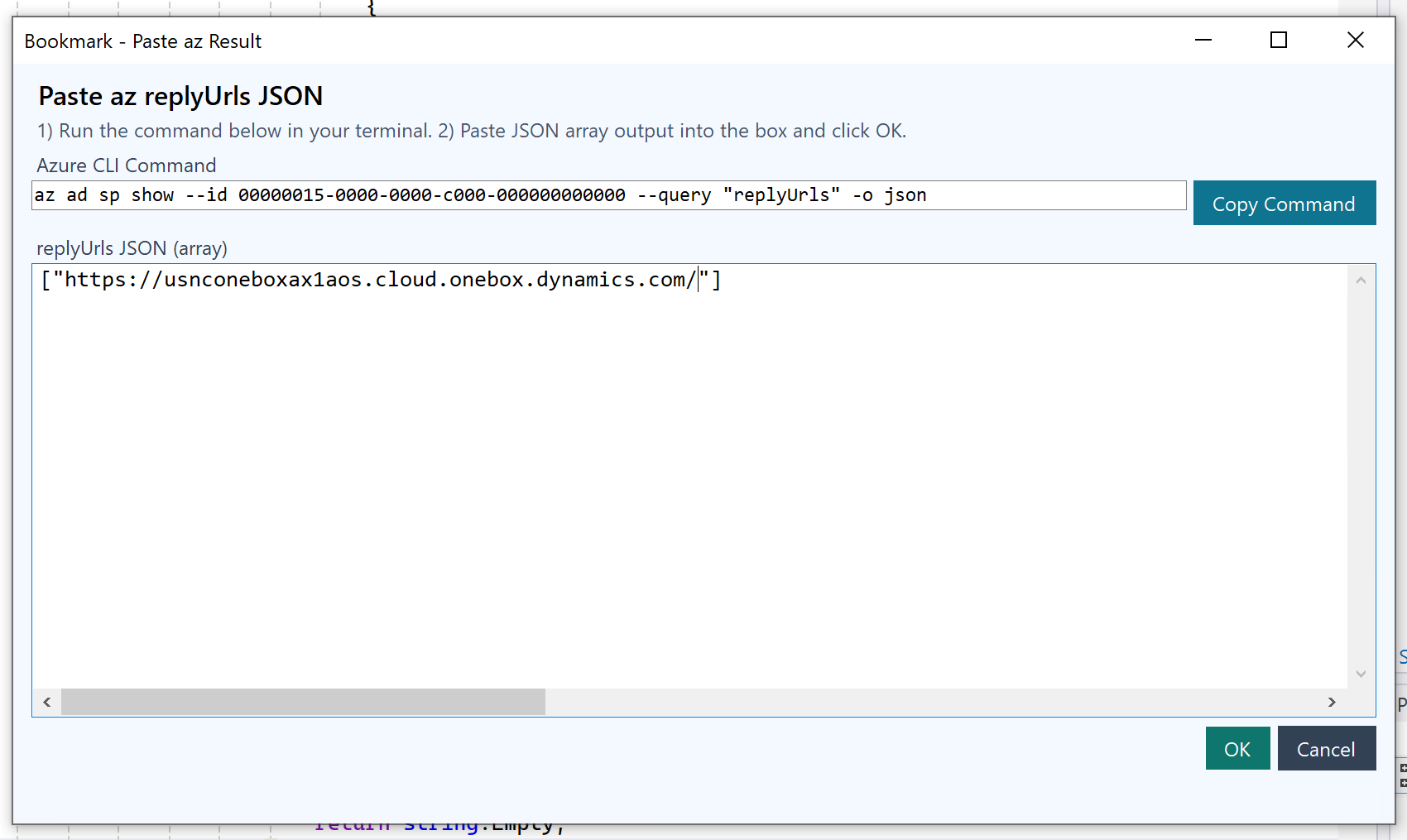
第七折: Host 为什么不用代码自动拿,非得让用户手动输一份列表? 这个问题我一开始其实也不服。
我当时想的是,环境 Host 这种信息,理论上完全可以自动化,能不能直接接 Azure 登录、调接口、把 replyUrls 或环境地址直接拿下来?
然后现实给了我一记标准的 D365 开发生态组合拳。
如果我在这个 Addin 里引入诸如 Microsoft.Identity.Client.MSAL 之类的认证库,看着是优雅了,实际上风险非常大。因为这个插件不是一个随便自娱自乐的独立 EXE,它是运行在 D365 开发插件上下文里的。
这意味着依赖版本必须和宿主环境严格匹配。
一旦你把不合适版本的库拎进来,就特别容易发生库冲突。更要命的是,这种冲突还不一定当场炸在插件功能上,它可能在你 Build 模型时用一种特别离谱的方式报复你。
比如由于认证相关依赖冲突,导致无法认证到 RDL 服务器,最后 Report 编译失败。
你本来只是想“顺手自动拿个 Host”,最后把整个开发环境的构建链子拧歪了,这不是给自己上强度么。
所以我最后做了一个看起来“没那么智能”,但实际上非常稳的方案:
插件弹窗给出命令。
用户自己跑 Azure CLI。
把 JSON 粘回来。
插件解析出 Host 列表,让用户勾选。
对应实现不是一句两句,而是整个弹窗流程都做出来了,先给命令,再让用户粘 JSON,再从里面筛 Host:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 Task<string > ShowHostInputDialogAsync (string azCommand, Action<string > writeOutput { return RunOnUiWithResultAsync(() => { ThreadHelper.ThrowIfNotOnUIThread(); try { using (var form = new Form()) { form.Text = R("HostInputDialog_Title" , "Bookmark - Paste az Result" ); form.StartPosition = FormStartPosition.CenterScreen; form.ClientSize = new Size(900 , 670 ); form.MinimumSize = new Size(820 , 600 ); form.BackColor = Color.FromArgb(244 , 248 , 255 ); form.Font = new Font("Segoe UI" , 9F ); var commandBox = new TextBox { Left = 24 , Top = 116 , Width = 742 , Height = 28 , ReadOnly = true , BackColor = Color.White, Font = new Font("Consolas" , 9F ), Text = azCommand }; var textBox = new TextBox { Left = 24 , Top = 182 , Width = 852 , Height = 418 , Multiline = true , ScrollBars = ScrollBars.Both, WordWrap = false , BackColor = Color.White, Font = new Font("Consolas" , 10F ) }; form.Controls.Add(commandBox); form.Controls.Add(textBox); if (form.ShowDialog() == DialogResult.OK) { return textBox.Text ?? string .Empty; } return string .Empty; } } catch (Exception ex) { writeOutput?.Invoke(RF("Output_HostInputDialogError" , "Host input dialog error: {0}" , ExceptionToLogText(ex))); return string .Empty; } }); } Task<List<string >> ShowHostSelectionDialogAsync(List<string > parsedHosts, Action<string > writeOutput) { return RunOnUiWithResultAsync(() => { ThreadHelper.ThrowIfNotOnUIThread(); var allHosts = (parsedHosts ?? new List<string >()) .Where(h => !string .IsNullOrWhiteSpace(h)) .Select(h => h.Trim()) .Distinct(StringComparer.OrdinalIgnoreCase) .OrderBy(h => h, StringComparer.OrdinalIgnoreCase) .ToList(); if (allHosts.Count == 0 ) { return new List<string >(); } return allHosts; }); }
这个方案的技术哲学很朴素:
不是不能自动化,而是自动化的代价,在这个宿主环境里太高,甚至高到会影响整个开发链路稳定性,调试还麻烦。
这时候,“让用户多复制粘贴一步”,反而是更工程化的选择。
说得再接地气一点: 你非要在拖拉机上装赛车点火模块,理论上也不是不行,但它一旦窜了,你一地找螺丝。
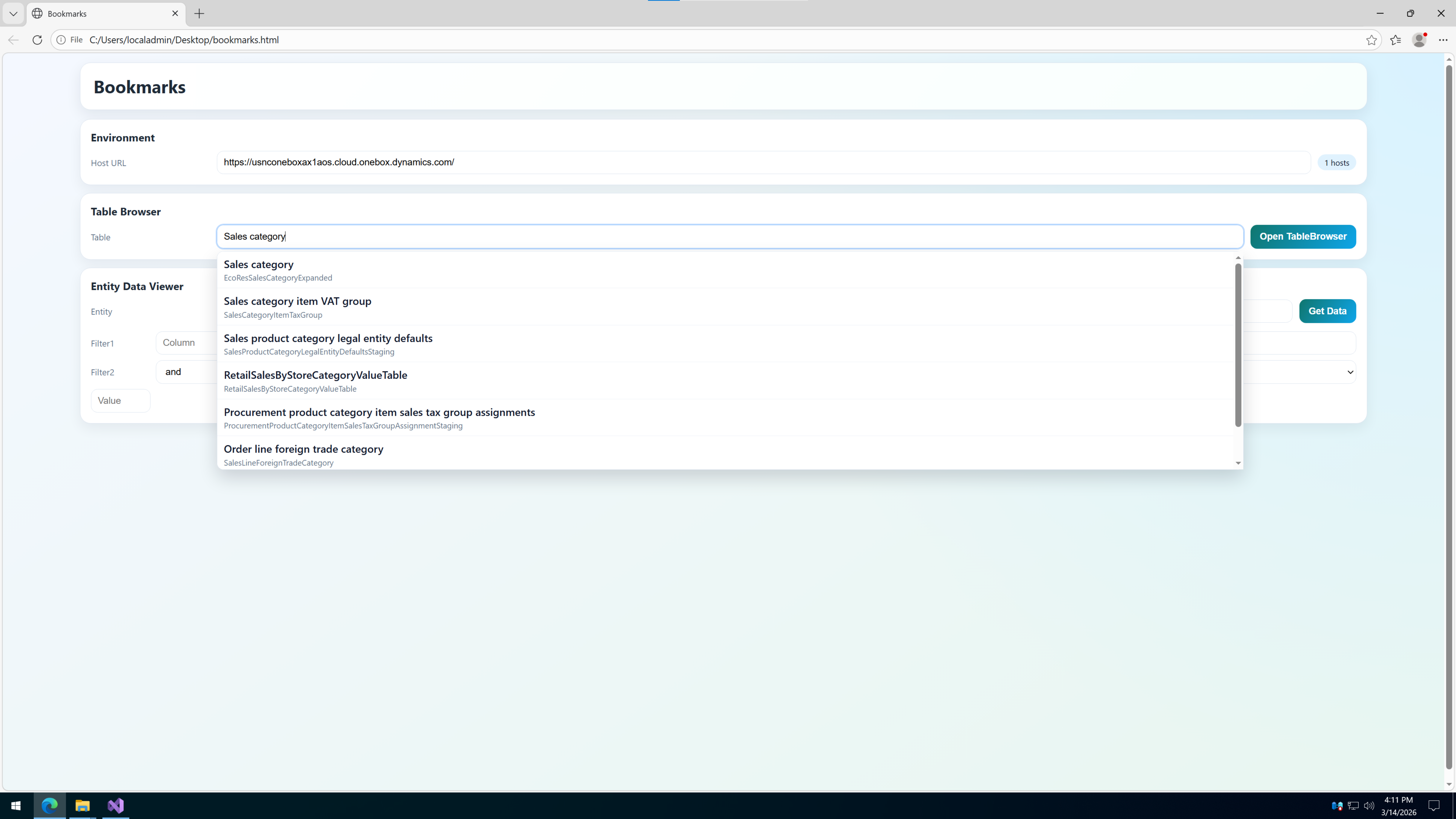
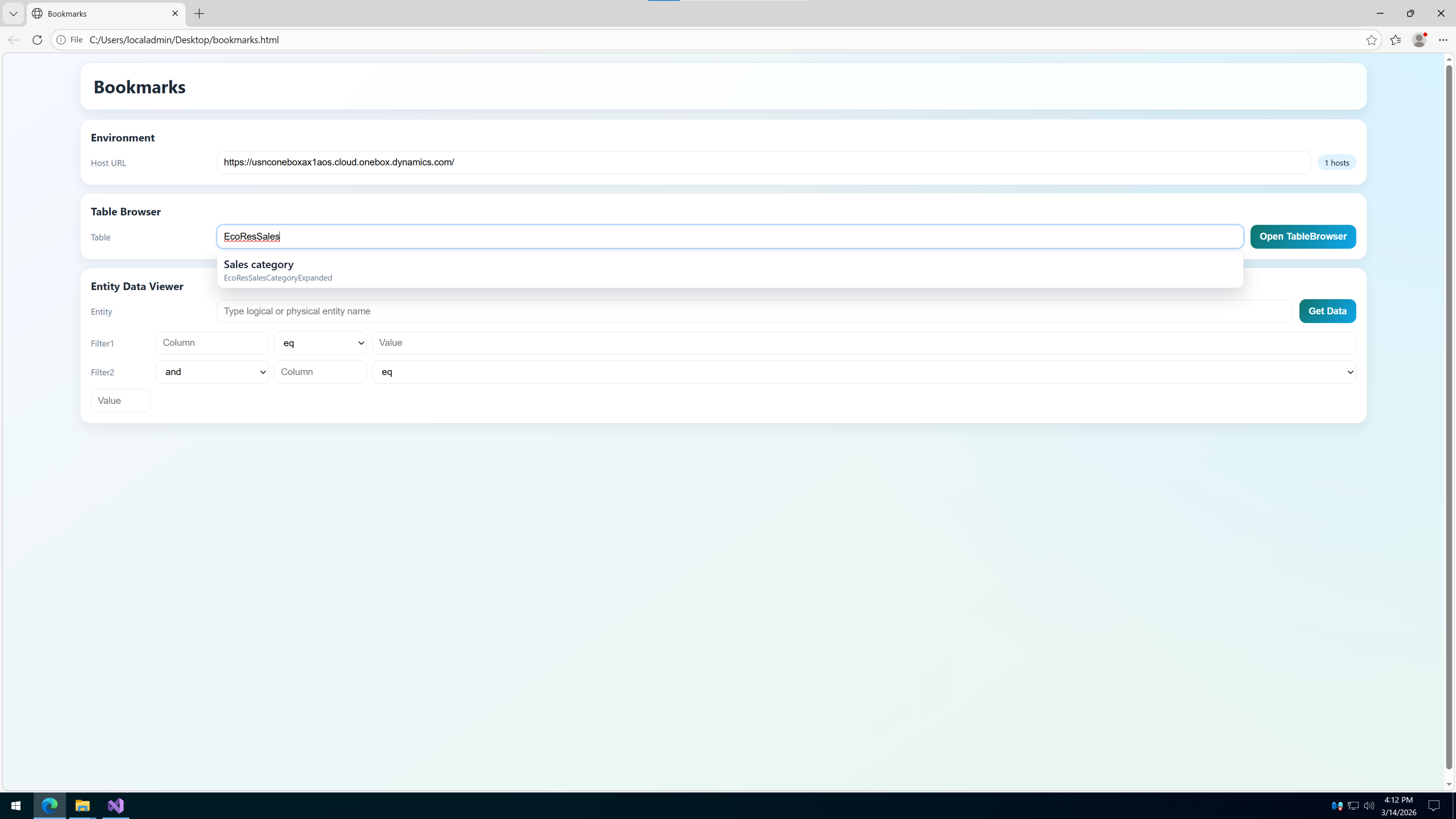
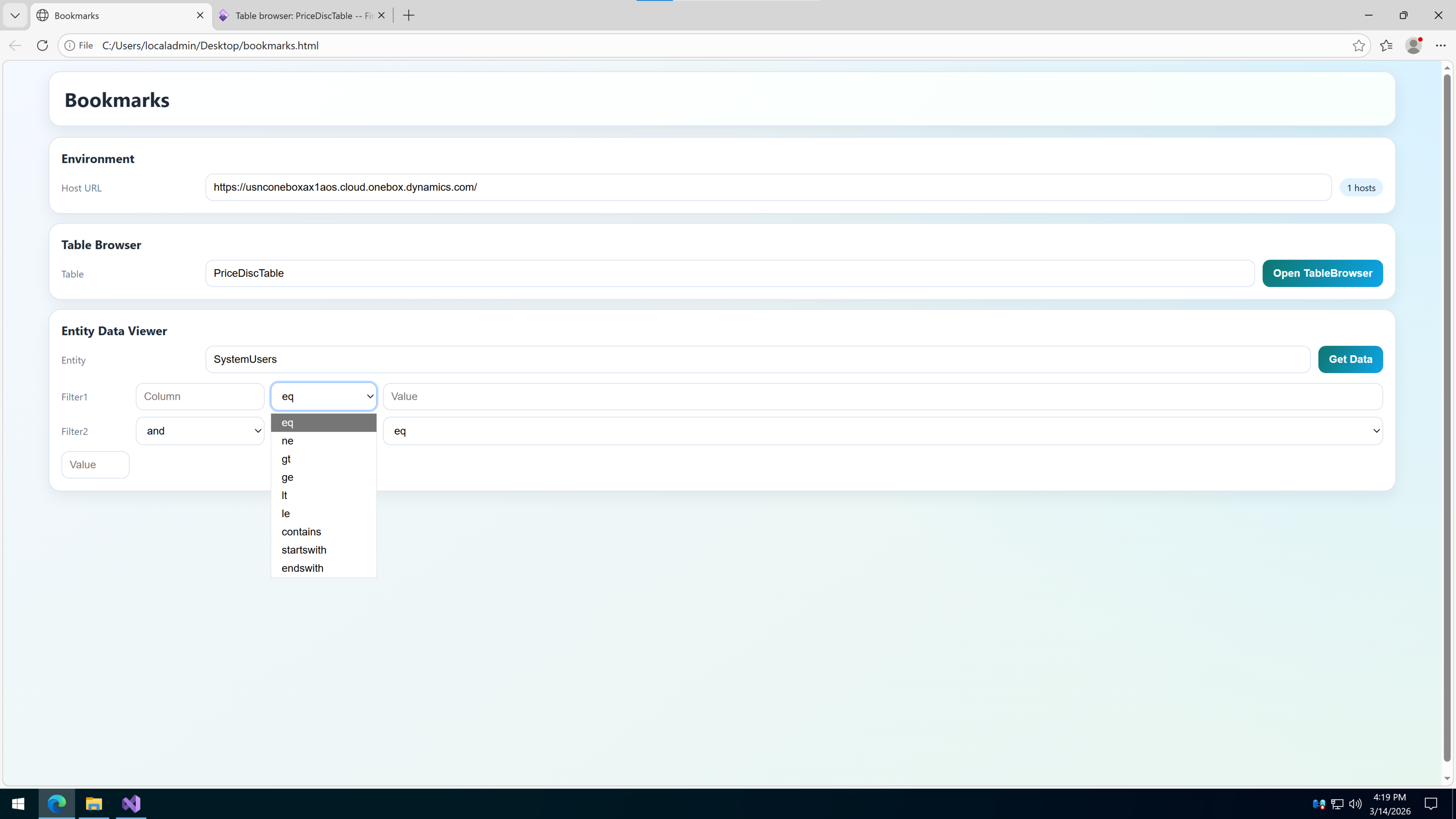
第八折: 生成 HTML 不是重点,重点是它得真能拿去用 元数据找到了,Host 也有了,剩下的就是把东西塞进 HTML 里,生成一个顺手能用的小页面。
这个页面干两件事:
根据 Host 和 Table 名,拼 SysTableBrowser 地址。
根据 Host、Entity 名和筛选条件,拼 OData 请求地址。
这部分前端脚本我也没整成花架子,而是把最核心的行为都写死在生成出来的 HTML 里,打开就能用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 function getEnvironmentUrl ( var env = document .getElementById ('environment' ).value .trim (); if (!env) { alert ('Please select or input a host.' ); return null ; } if (!/^https?:\/\//i .test (env)) { env = 'https://' + env; } if (!env.endsWith ('/' )) { env += '/' ; } return env; } function openTableBrowser ( var url = getEnvironmentUrl (); if (!url) return ; var tableParm = document .getElementById ('table' ).value .trim (); if (!tableParm) { alert ('Please input a table name.' ); return ; } var tablePhysical = resolvePhysicalName (tableParm, tableMap); window_A = window .open (url + '?&mi=SysTableBrowser&Tablename=' + encodeURIComponent (tablePhysical), Date ()); } function getData ( var url = getEnvironmentUrl (); if (!url) return ; var entityParm = document .getElementById ('entity' ).value .trim (); if (!entityParm) { alert ('Please input an entity name.' ); return ; } var entityPhysical = resolvePhysicalName (entityParm, entityMap); var col1 = document .getElementById ('col1' ).value ; var operator1 = document .getElementById ('operator1' ).value ; var val1 = document .getElementById ('val1' ).value ; var c1 = buildCondition (col1, operator1, val1); var endpoint = url + 'data/' + encodeURIComponent (entityPhysical) + '/' ; var query = '?$top=10' ; if (c1) { query += '&$filter=' + encodeURIComponent (c1); } window_A = window .open (endpoint + query, Date ()); }
我在这里故意把逻辑名和物理名都保留下来,一方面是为了搜索体验,另一方面也是为了防止用户只记得业务名称,不记得实际对象名称。
这点特别真实。
很多时候你脑子里记的是“客户发票行”这种中文或者语义化名字,真让你手敲物理名,立马开始发懵。
工具的价值,不就是在你发懵之前先替你兜一手么。
第九折: csproj 里输出复制策略为什么要改,只复制主 DLL? 这块也是我后来越用越烦,最后果断改掉的地方。
最开始如果这么写:
1 <OutputFiles Include ="$(MSBuildProjectDirectory)\$(OutputPath)\**\*.*" />
那意思就是把输出目录下所有东西一股脑复制进 AddinExtensions。
听着挺省事,是吧?
但实际效果就是目录越堆越乱,文件一大坨,瞅着就闹心。而且这个项目本来引用的大部分库,都是从同版本环境里来的,并不需要你再整包复制过去。
所以我把它改成了只复制主 DLL:
现在实际配置是:
1 2 3 4 5 6 7 8 <Target Name ="AfterBuildAction" Condition ="'$(BuildingInsideVisualStudio)'=='true'" AfterTargets ="AfterBuild" > <ItemGroup > <OutputFiles Include ="$(MSBuildProjectDirectory)\$(OutputPath)\**\Dynamics.Framework.Tools.AddIns.Bookmark.17.0.dll" /> </ItemGroup > <Message Text ="Copying @(OutputFiles) to $(DynamicsVSToolsHintPath)\AddinExtensions" Importance ="high" /> <Copy SourceFiles ="@(OutputFiles)" DestinationFiles ="@(OutputFiles->'$(DynamicsVSToolsHintPath)\AddinExtensions\%(RecursiveDir)%(Filename)%(Extension)')" /> <Message Text ="Copying finished" Importance ="high" /> </Target >
为什么这么改?
因为依赖本身已经来自对应版本环境,不需要把一堆引用 DLL 再抄一遍。
因为全复制会导致 Addin 目录特别杂乱,后期维护和排查都难受。
因为这个插件只靠主 DLL 就能运行。
因为发布的时候也更清爽,拿一个主产物就够了。
这属于典型的“早期图省事,后期给自己埋雷”。
改完之后整个输出目录都顺眼不少,真有一种把阳台纸壳箱清出去的畅快感。
最后这一哆嗦: 为什么每次测试完还得关 VS 重开,太抽象了 写到这儿,功能其实已经差不多全了。
但是,真正折磨人的往往不是功能本身,而是测试闭环。
这个 Addin 每次测试完,如果你还想继续 Build,经常会遇到一个非常经典、非常气人、非常 Visual Studio 、非常 Microsoft 的问题:
插件 DLL 已经被 VS 自己加载了,文件被占用,新的 DLL 复制不过去。
于是你一 Build,它就开始跟你摆脸子。
你看着错误信息,心里也明白是咋回事,但还是会忍不住来一句: 不是哥们,你加载的是你,锁文件的也是你,现在你不让我复制,咋的,全宇宙都得配合你脾气呗?
最后最稳定的办法,往往还是:
测完。
关掉 VS。
重开 VS。
再 Build。
这套流程不优雅,甚至有点原始,但它有效。(其实如果把复制去了也行,就得手动搬dll,我嫌麻烦)
抽象 VS,诚不欺我。
我最后得到的结论 折腾这一圈下来,我对这类开发扩展工具的理解反而更清楚了。
真正可靠的方案,往往不是“理论上最先进”的那条,而是“在当前宿主约束下最不容易翻车”的那条。
所以这个 Bookmark Addin 最后的技术路线,其实非常工程化:
不碰 SQLDictionary 和 SysTableIdTable 这种容易把数据整乱的来源。
不依赖手动刷新的 Entity 列表。
直接走 Disk Metadata,贴近当前开发态。
先 ListObjects,再 Read,把枚举和读取拆开。
用 IMetadataProvider.Tables.Read 这套,绕开 IIS 上下文依赖。
Host 不在插件内强上认证链路,改为用户输入和粘贴 JSON,避开依赖冲突。
发布产物只复制主 DLL,减少 Addin 目录污染。
你要说这套方案是不是最花哨的?那真不是。
但你要问它是不是在 D365FO 这种环境里足够稳、足够实用、足够少整幺蛾子的?
我可以很负责任地说: 那可太是了。
后记 现在回头看,这插件最有意思的地方,不是我最后做出了一个 Bookmark 页面,而是它逼着我重新理解了一遍 D365FO 开发工具链的边界。
有些东西你在业务代码里觉得理所当然,换个宿主就不是那回事了。
有些东西你以为“自动化一定更高级”,结果真正落到工程实践里,手动一步反而更稳。
有些坑你第一次踩的时候觉得离谱,等你踩完一圈再回头看,又会觉得: 行吧,虽然抽象,但也算讲理。
这开发过程怎么说呢。
一开始我是想省事,最后是边骂边改;中间以为自己走进死胡同,结果拐个弯又通了;等真跑起来的时候,又有一种“哎妈呀总算整明白了”的朴素快乐。
如果你也在 D365FO 的开发扩展、元数据读取、插件宿主兼容这些地方反复拉扯,希望这篇能帮你少走两步冤枉路。
要不然真容易整到最后,屏幕一关,脑瓜子嗡嗡的, 恨不得把公司笔记本嵌墙里(别弄,得赔)。
对了,高版本很多框架库要.net framework 4.8 了,4.7.2 会编译不过哦。